sd.keydrop.net ユーザーマニュアル
sd.keydrop.net は、ブラウザ内の WebGPU で AI 画像生成を行う完全ローカルのツールです。Stable Diffusion 互換モデルに対応しています。 サーバーにデータを送信しない設計のため、プロンプト・モデル・生成画像のプライバシーが保たれます。
本マニュアルでは、モデルの入手から画像生成、LoRA マージ、設定変更、トラブルシューティングまでを解説します。
動作環境
sd.keydrop.net はブラウザ内の WebGPU で AI 推論を行うため、一般的な Web アプリよりも高いスペックが必要です。 使用するモデルの種類によって要求が大きく変わります。
Mac
| 項目 | 最小スペック | 推奨スペック |
|---|---|---|
| チップ | Apple M1 | Apple M2 Pro / M3 Pro 以上 |
| メモリ (RAM) | 8GB(SD-Turbo のみ) | 32GB 以上 |
| GPU メモリ | 統合メモリ(RAM と共有) | |
| ストレージ | 5GB 空き | 30GB 以上の空き |
| OS | macOS 13+ | macOS 14+ |
| ブラウザ | Chrome 121+ / Arc / Edge(Safari 非対応) | |
Windows
| 項目 | 最小スペック | 推奨スペック |
|---|---|---|
| GPU | NVIDIA GTX 1060 (VRAM 6GB) | NVIDIA RTX 3060 Ti (VRAM 8GB) 以上 |
| メモリ (RAM) | 8GB | 32GB 以上 |
| VRAM | 4GB(SD-Turbo のみ) | 8GB 以上 |
| ストレージ | 5GB 空き | 30GB 以上の空き |
| OS | Windows 10 | Windows 11 |
| ブラウザ | Chrome 121+ / Edge 121+ / Arc | |
モデル別のスペック要求
ブラウザはモデルファイル全体をメモリに読み込むため、モデルのファイルサイズ ≒ 必要な RAM と考えてください。
外部データファイル(.onnx.data)がある場合はそのサイズも加算されます。
| モデル | ファイル合計 | 必要 RAM | 必要 VRAM | 解像度 |
|---|---|---|---|---|
| SD-Turbo (fp16) | ~2GB | 8GB | 4GB | 512×512 |
| SD 1.5 (weight-only fp16) | ~2GB | 8GB | 4GB | 512×512 |
| SDXL (fp32) ❌ | ~13GB | 32GB 以上 | 8GB | 1024×1024 (現時点では動作不可) (軽量版 Segmind Vega は ~1.4GB で動作の可能性あり) |
SDXL の UNet は fp16 でも約 4.8GB あり、ブラウザの 1 タブに割り当てられるメモリ上限(通常 4〜8GB)を超えるため、現時点では動作しません。 これは PC の RAM やスペックに関係なく、ブラウザ(Chrome / Edge / Arc)のアーキテクチャ上の制限です。
sd.keydrop.net では SD-Turbo および SD 1.5 系モデルを推奨します。 将来ブラウザのメモリ制限が緩和されるか、SDXL の軽量化モデルが登場した場合に対応を再検討します。
対応ブラウザ
| ブラウザ | WebGPU | 対応状況 |
|---|---|---|
| Chrome 121+ | ✅ デフォルト有効 | 推奨 |
| Edge 121+ | ✅ デフォルト有効 | 対応 |
| Arc | ✅ デフォルト有効 | 対応 |
| Safari | ⚠️ Tech Preview のみ | 非対応 |
| Firefox | ⚠️ Nightly のみ | 非対応 |
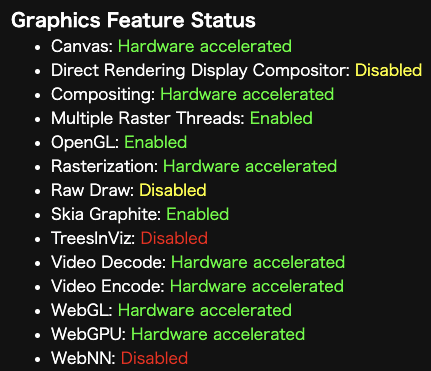
WebGPU が使えるか確認する方法
Chrome で chrome://gpu を開き、「WebGPU」が「Hardware accelerated」になっていれば OK です。
モデルの入手
sd.keydrop.net はモデルを同梱していません。ユーザーが自身でモデルファイルを入手してアップロードする必要があります。
推奨: SD-Turbo(初心者向け)
最も手軽に試せるのは SD-Turbo です。1〜4 ステップで画像生成でき、VRAM 要求も 4GB と控えめです。
# ダウンロードスクリプト(開発環境のみ)
./scripts/download-sd-turbo.sh ~/Downloads/sd-turbo
スクリプトが使えない環境では、Hugging Face の
schmuell/sd-turbo-ort-web
リポジトリから以下の 5 ファイルを手動ダウンロードしてください:
text_encoder/model.onnx(約 650MB) →text_encoder.onnxにリネームunet/model.onnx(約 1.6GB) →unet.onnxにリネームvae_decoder/model.onnx(約 95MB) →vae_decoder.onnxにリネームtokenizer/vocab.json(約 1MB)tokenizer/merges.txt(約 500KB)
text_encoder / unet / vae が含まれている必要があります(アプリがファイル名で自動分類するため)。
その他のモデル
SD 1.5 系や SDXL の ONNX 変換済みモデルも対応しています。Hugging Face で
onnx stable-diffusion や Xenova/stable-diffusion-v1-5 などで検索してください。
SDXL は VRAM 8GB 以上が推奨です。
おすすめモデル一覧
以下は sd.keydrop.net での動作確認状況をまとめたモデルリストです。
SD-Turbo / 少ステップ系(推奨・初心者向け)
1〜8 ステップで画像生成が完了する蒸留モデル。ブラウザ環境で最も快適に使えます。
| モデル名 | 入手先 | ステップ数 | UNet (fp16) | 変換 | 動作 | 特徴 |
|---|---|---|---|---|---|---|
| SD-Turbo ORT Web | schmuell/sd-turbo-ort-web | 1〜4 | ~1.6GB | 不要 | ✅ 確認済み | 最もおすすめ。ORT Web 向け最適化済み。ダウンロードしてそのまま使える |
| SD-Turbo | stabilityai/sd-turbo | 1〜4 | ~1.7GB | Colab/ローカル | ✅ | Stability AI 公式。CFG 不要 |
| LCM DreamShaper v7 | SimianLuo/LCM_Dreamshaper_v7 | 4〜8 | ~1.7GB | Colab/ローカル | ⚠️ 要テスト | DreamShaper ベースの LCM。画風のバリエーション |
- SD-Turbo: SD 2.1 ベース。1 step で生成可能。CFG 不要。LoRA 非対応。画風は固定
- LCM (Latent Consistency Model): SD 1.5 系ベースの蒸留。4〜8 step。ベースモデルの画風を引き継ぐため種類が豊富。LoRA も利用可能(ベースモデル依存)
SD 1.5 系(高品質・LoRA 豊富)
| モデル名 | 入手先 | 特徴 | UNet サイズ (ONNX fp32) | 動作 |
|---|---|---|---|---|
| Stable Diffusion 1.5 (base) | Hugging Face (runwayml/stable-diffusion-v1-5) | ベースモデル。LoRA の互換性が最も高い | ~1.7GB | ✅ |
| Anything V5 | CivitAI | アニメ系の定番 | ~1.7GB | ✅ |
| Realistic Vision V5.1 | CivitAI | フォトリアル系の定番 | ~1.7GB | ✅ |
| DreamShaper 8 | CivitAI | 汎用。写真からイラストまで | ~1.7GB | ✅ |
| MeinaMix V11 | CivitAI | アニメ・イラスト特化 | ~1.7GB | ✅ |
| CounterfeitV3.0 | CivitAI | アニメ系、高品質 | ~1.7GB | ✅ |
dtype='fp16' で出力された純粋な fp16 ONNX モデルは ONNX Runtime Web で正しく動作しないため、必ず変換ガイドの手順に従ってください。
SDXL 系(現時点では非対応)
| モデル名 | UNet サイズ (fp16) | 動作 | 理由 |
|---|---|---|---|
| Nova Anime XL | ~4.8GB | ❌ | ブラウザのタブメモリ上限超過 |
| Animagine XL 3.1 | ~4.8GB | ❌ | 同上 |
| Juggernaut XL | ~4.8GB | ❌ | 同上 |
| RealVisXL | ~4.8GB | ❌ | 同上 |
| Pony Diffusion V6 XL | ~4.8GB | ❌ | 同上 |
SDXL 軽量モデル(動作の可能性あり)
SDXL の UNet を蒸留(distillation)して小型化したモデルです。解像度は SDXL と同じ 1024×1024 を維持しつつ、UNet のパラメータ数を大幅に削減しています。
| モデル名 | 入手先 | パラメータ数 | UNet (fp16 推定) | 解像度 | 動作見込み | 特徴 |
|---|---|---|---|---|---|---|
| Segmind Vega | Hugging Face | 0.74B | ~1.4GB | 1024×1024 | ✅ 可能性高い | SDXL の UNet を約 1/3 に蒸留。SD-Turbo 並のサイズ |
| SSD-1B | Hugging Face | 1.3B | ~2.4GB | 1024×1024 | ⚠️ 要テスト | SDXL の UNet を約半分に蒸留。ブラウザのメモリ上限ギリギリ |
- SDXL と同じ VAE / テキストエンコーダを使うため、1024×1024 で生成可能
- 一部の SDXL 向け LoRA も利用可能(互換性は限定的)
- Colab での変換時は
StableDiffusionXLPipeline.from_pretrained("segmind/Segmind-Vega")を使用(from_single_fileではなくfrom_pretrained)
# Google Colab のセル 4 を以下に差し替えて使用
from diffusers import StableDiffusionXLPipeline
import torch
pipe = StableDiffusionXLPipeline.from_pretrained(
"segmind/Segmind-Vega", # or "segmind/SSD-1B"
torch_dtype=torch.float16
)
pipe.save_pretrained('./model-diffusers')
# 以降は通常の SDXL 変換と同じ手順SDXL-Turbo / Lightning(将来対応の可能性)
SDXL-Turbo や SDXL-Lightning は SDXL ベースですが、ステップ数が少ないためやや軽量です。 ただし UNet サイズは同じ ~4.8GB のため、現時点では同様に動作しません。 ブラウザのメモリ制限が緩和された場合に対応を検討します。
dtype='fp16' で出力された純粋な fp16 モデルは ONNX Runtime Web で正しく動作しません(出力がほぼゼロ値になる)。SD 1.5 系は必ず「weight-only fp16」変換ガイドの手順で変換してください。
モデルの読み込み
- 「画像生成」タブを開きます。左サイドバーにモデル選択パネルがあります。
-
「ここにファイルをドロップ」エリアに、5 ファイルすべてを一度にドラッグ&ドロップします。
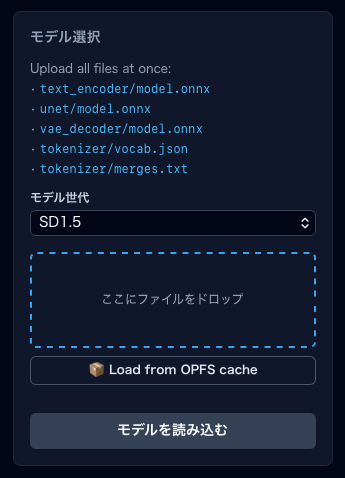
- 世代を選択(SD1.5 / SDXL / SD3)。ファイル名から自動推測されることが多いので、変更が不要な場合はそのまま。
- 「モデルを読み込む」ボタンをクリック。
-
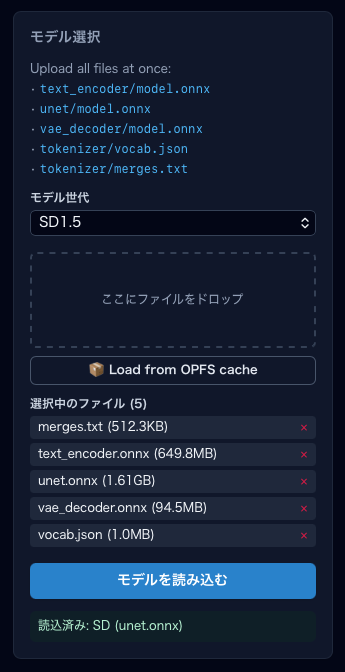
進捗表示が始まります:
📥 Loading (10%): Reading text_encoder— ファイル読み込み🔧 Compiling shaders (10%): Compiling text_encoder for WebGPU— WebGPU シェーダーコンパイル- UNet (50%) → VAE (85%) → Tokenizer (95%) と進む
初回はシェーダーコンパイルで数十秒〜数分かかることがあります。2 回目以降はブラウザキャッシュにより高速化されます。 -
「Model loaded: SD-Turbo (unet.onnx)」のトーストが表示されれば成功です。
OPFS キャッシュからの復元
一度アップロードしたモデルは OPFS(Origin Private File System) に自動保存されます。 次回以降は、ドロップゾーンの下にある「📦 Load from OPFS cache」ボタンをクリックするだけで復元できます。
画像を生成する
プロンプト入力
中央のパネルにプロンプト(Positive / Negative)を入力します。CLIP ViT-L は英語で学習されているため、英語でのプロンプトを推奨します。
例:
Prompt: a cute orange tabby cat sitting on a red sofa, photorealistic, 4k
Negative: blurry, low quality, watermark
生成パラメータ
| 項目 | 説明 | SD-Turbo 推奨値 |
|---|---|---|
| 幅 / 高さ | 出力画像の解像度 | 512 / 512 |
| Steps | サンプリングステップ数(多いほど精緻だが遅い) | 1(最速)〜 4 |
| CFG Scale | プロンプトへの忠実度(高いほど忠実だがアーティファクトが出やすい) | 0(Turbo は内部で無効化) |
| Seed | ノイズの初期値。同じ seed + 同じ設定 → 同じ画像 | 任意の整数 |
生成実行
- パラメータを設定したら「生成」ボタンをクリック
- 進捗バーが表示されます(ステップ数に応じた進行)
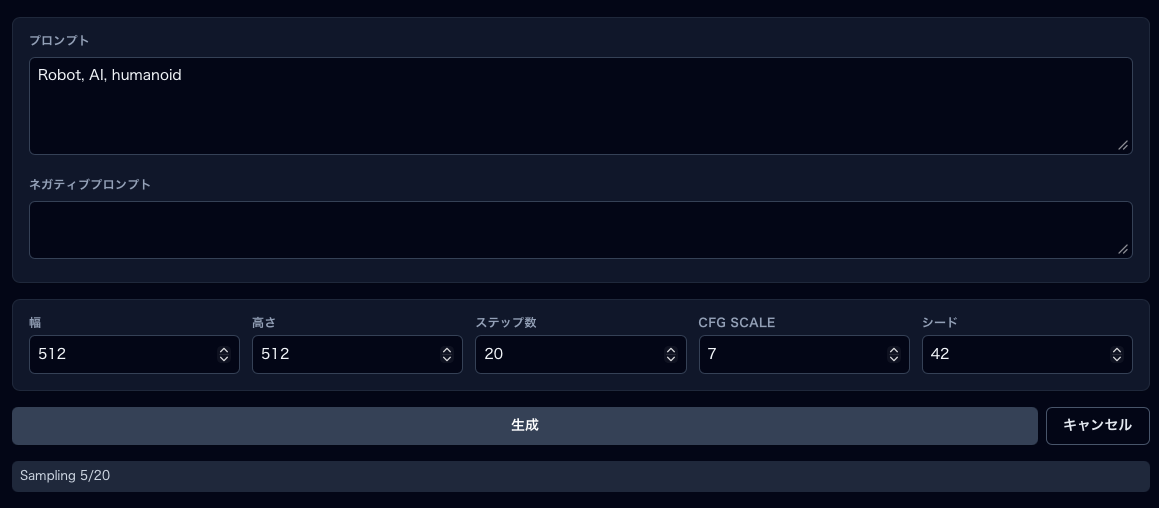
- 完了すると右パネルに画像が表示されます
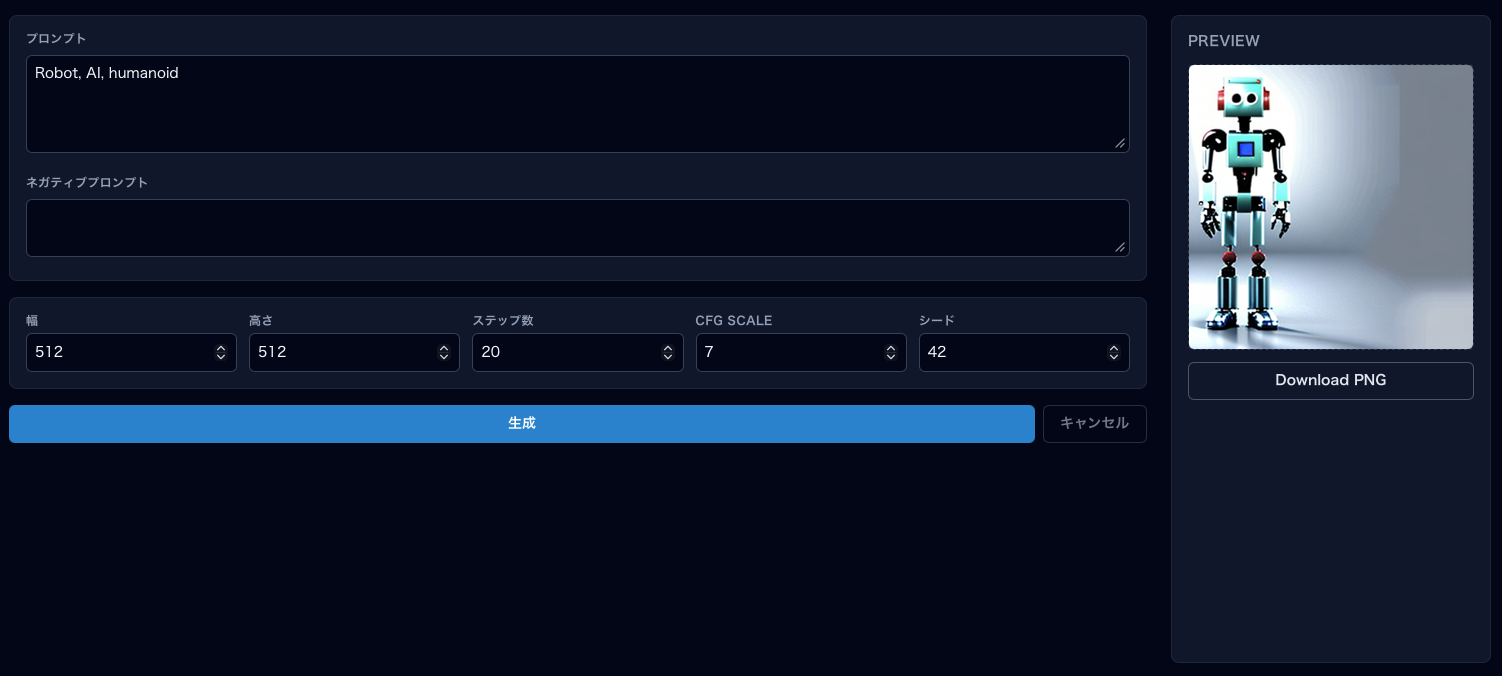
- 「Download PNG」ボタンでローカルに保存
PNG メタデータ
ダウンロードされた PNG には、生成パラメータ(プロンプト / サイズ / Steps / CFG / Seed / モデル名 / エンジン)が tEXt チャンクとして自動埋込されます。AUTOMATIC1111 や ComfyUI の「PNG Info」機能で読み取れます。
キャンセル
生成中に「キャンセル」ボタンを押すと、Worker に中断指令が送られます。
LoRA について
LoRA(Low-Rank Adaptation)は、ベースモデルに追加のスタイルやキャラクター表現を注入する軽量な追加学習手法です。 sd.keydrop.net では事前マージ方式を採用しています。
ワークフロー:
- ベースモデル(.safetensors)と LoRA(.safetensors)を用意
- 「LoRA マージ」タブでマージを実行
- マージ済み .safetensors をダウンロード
- オフラインで ONNX に変換(別途ツールが必要)
- 変換した ONNX モデルをアプリにアップロードして生成
LoRA マージ手順
-
「LoRA マージ」タブを開きます。
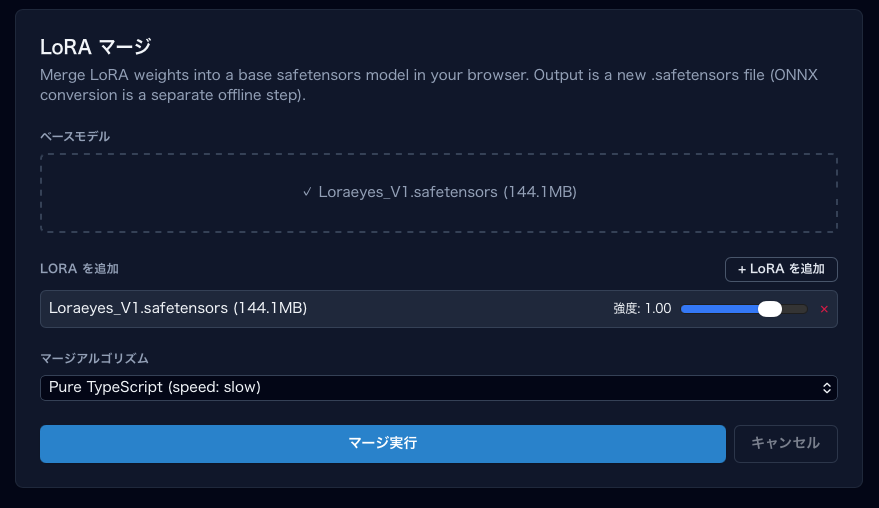
-
ベースモデル(.safetensors 形式)をドロップエリアに投下します。
例:v1-5-pruned-emaonly.safetensors - 「+ LoRA を追加」ボタンで LoRA ファイル(.safetensors)を追加します。複数追加可能。
-
各 LoRA の weight スライダーを調整します。
1.0— 通常強度0.5— 弱め1.5— 強め-1.0— 逆効果
- マージアルゴリズムを選択(現状は「Pure TypeScript」のみ対応)。
-
「マージ実行」ボタンをクリック。進捗バーが表示されます。
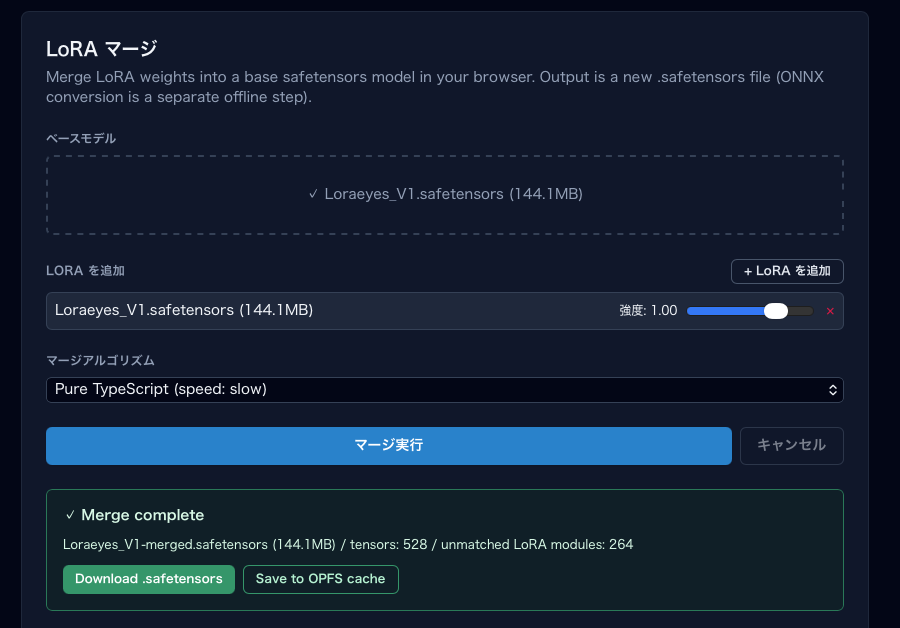
-
完了後:
- 「Download .safetensors」 — マージ済みファイルを PC に保存
- 「Save to OPFS cache」 — ブラウザ内ストレージに保存
マージ結果のメタデータ
出力ファイルの __metadata__ には以下が記録されます:
{
"format": "pt",
"merged_with": "my-lora.safetensors@1.0; other-lora.safetensors@0.5",
"merged_at": "2026-04-10T...",
"merged_by": "sd.keydrop.net pure-ts",
"unmatched_lora_modules": "0"
}
unmatched_lora_modules がゼロでない場合は、LoRA のキー名がベースモデルのキー名にマッチしなかったモジュールがあることを示しています。
safetensors → ONNX 変換ガイド
CivitAI / Hugging Face のモデルを sd.keydrop.net で使うための変換手順です。 変換方法は 2 つあります。
| 方法 | 対象 | 所要時間 | 必要なもの |
|---|---|---|---|
| 方法 1: Google Colab(推奨) | SD 1.5 / SDXL 全て | 10〜15 分 | Google アカウントのみ |
| 方法 2: ローカルスクリプト | SD 1.5 のみ実用的 | 5〜30 分 | Python 3.12 + NVIDIA GPU(SDXL は数時間かかり非推奨) |
方法 1:Google Colab で変換(推奨)
ブラウザから無料の GPU を使って変換します。PC のスペックに関係なく、SD 1.5 / SDXL どちらも変換できます。
手順
- Google Colab を開き、「新しいノートブック」を作成
- メニューの 「ランタイム」→「ランタイムのタイプを変更」→ ハードウェアアクセラレータを「T4 GPU」に設定して保存
- 以下の 6 つのセルを順番にコピー&ペーストして実行(各セルの左にある ▶ ボタンをクリック)
セル 1: ライブラリインストール(約 3 分)
!pip install -q optimum[onnxruntime-gpu] diffusers transformers torch accelerate
print("✅ インストール完了")セル 2: モデルファイルをアップロード
from google.colab import files
print("safetensors ファイルを選択してください...")
uploaded = files.upload()
model_filename = list(uploaded.keys())[0]
print(f"✅ アップロード完了: {model_filename} ({len(uploaded[model_filename]) / 1e9:.1f}GB)")ファイル選択ダイアログが表示されるので、CivitAI 等からダウンロードした .safetensors を選択してください。
セル 3: モデルタイプを選択
# SD 1.5 系の場合は "sd15" に変更してください
MODEL_TYPE = "sdxl"
if MODEL_TYPE == "sdxl":
PIPELINE_CLASS = "StableDiffusionXLPipeline"
TASK = "stable-diffusion-xl"
else:
PIPELINE_CLASS = "StableDiffusionPipeline"
TASK = "stable-diffusion"
print(f"✅ モデルタイプ: {MODEL_TYPE}")MODEL_TYPE = "sd15" に変更してから実行してください。
セル 4: 変換実行(約 10〜15 分)
import torch, os, shutil, gc
from pathlib import Path
# Step 1: safetensors → diffusers(fp32 で読み込み)
print("📦 Step 1/4: diffusers 形式に変換中...")
if MODEL_TYPE == "sdxl":
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_single_file(model_filename, torch_dtype=torch.float32)
else:
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_single_file(model_filename, torch_dtype=torch.float32)
pipe.save_pretrained('./model-diffusers')
del pipe; torch.cuda.empty_cache()
print("✅ diffusers 変換完了")
# Step 2: ONNX (fp32) エクスポート
# ⚠️ dtype='fp16' は使わない — fp16 グラフはブラウザの ONNX Runtime Web で
# 正しく動作しないため、fp32 でエクスポートする
print("🔧 Step 2/4: ONNX (fp32) エクスポート中...(10〜15 分お待ちください)")
from optimum.exporters.onnx import main_export
try:
main_export(model_name_or_path='./model-diffusers', output=Path('./model-onnx'), task=TASK, no_post_process=True)
except Exception as e:
print(f"⚠️ 警告(ファイルは出力済み): {e}")
print("✅ ONNX エクスポート完了")
# Step 3: 重みを fp16 に変換(計算グラフは fp32 互換のまま)
print("🔄 Step 3/4: 重みを fp16 に変換中...")
import onnx
import numpy as np
from onnx import TensorProto, numpy_helper, helper
def convert_weights_to_fp16(model):
init_names = set()
for init in model.graph.initializer:
if init.data_type == TensorProto.FLOAT and init.name:
init_names.add(init.name)
if not init_names:
return model
print(f" Converting {len(init_names)} initializers to fp16...")
for init in model.graph.initializer:
if init.name in init_names:
np_data = numpy_helper.to_array(init)
np_fp16 = np_data.astype(np.float16)
new_tensor = numpy_helper.from_array(np_fp16, init.name)
init.CopyFrom(new_tensor)
cast_map = {}
cast_nodes = []
for name in init_names:
cast_out = name + '__fp32'
cast_node = helper.make_node(
'Cast', inputs=[name], outputs=[cast_out],
to=int(TensorProto.FLOAT), name=name + '__cast',
)
cast_nodes.append(cast_node)
cast_map[name] = cast_out
for node in model.graph.node:
for i in range(len(node.input)):
if node.input[i] in cast_map:
node.input[i] = cast_map[node.input[i]]
for out in model.graph.output:
if out.name in cast_map:
out.name = cast_map[out.name]
for inp in model.graph.input:
if inp.name in init_names:
inp.type.tensor_type.elem_type = int(TensorProto.FLOAT16)
for node in reversed(cast_nodes):
model.graph.node.insert(0, node)
print(f" Inserted {len(cast_nodes)} Cast nodes")
return model
os.makedirs('sd-ready', exist_ok=True)
components = [('text_encoder','text_encoder'),('text_encoder_2','text_encoder_2'),('unet','unet'),('vae_decoder','vae_decoder')]
for src, dst in components:
p = f'model-onnx/{src}/model.onnx'
if not os.path.exists(p): continue
print(f" {dst}: loading fp32 model...")
model = onnx.load(p, load_external_data=True)
print(f" {dst}: converting weights to fp16...")
model = convert_weights_to_fp16(model)
out = os.path.abspath(f'sd-ready/{dst}.onnx')
onnx.save(model, out)
del model; gc.collect()
print(f" {dst}: {os.path.getsize(out)/1e6:.0f}MB")
# Step 4: tokenizer コピー
print("📂 Step 4/4: tokenizer ファイルをコピー中...")
for f in ['vocab.json','merges.txt']:
s = f'model-onnx/tokenizer/{f}'
if os.path.exists(s): shutil.copy2(s, f'sd-ready/{f}')
print("\n🎉 変換完了!セル 5 でダウンロードしてください。")セル 5: ZIP に圧縮してダウンロード
import subprocess, os
subprocess.run(['zip', '-r', '-0', 'sd-ready.zip', 'sd-ready/'], check=True)
print(f"📦 sd-ready.zip ({os.path.getsize('sd-ready.zip')/1e9:.1f}GB)")
from google.colab import files
files.download('sd-ready.zip')ファイルが大きすぎてダウンロードが失敗する場合は、下のセル 5b を使ってください。
セル 5b: Google Drive に保存(大きなファイルの場合)
from google.colab import drive
import shutil
drive.mount('/content/drive')
shutil.copytree('sd-ready', '/content/drive/MyDrive/sd-ready', dirs_exist_ok=True)
print("✅ Google Drive の「マイドライブ/sd-ready」に保存しました")ダウンロード後
sd-ready.zipを解凍(または Google Drive からコピー)- sd.keydrop.net を開く
sd-ready/内の全ファイルをドロップ- 世代を選択して「モデルを読み込む」
方法 2:ローカルスクリプトで変換
- Python 3.10〜3.12(3.13 以上は非対応)
- SD 1.5: RAM 8GB 以上
- SDXL: NVIDIA GPU + RAM 16GB 以上
- ディスク空き容量 20GB 以上
まずスクリプトをダウンロード
以下のリンクからスクリプトをダウンロードし、変換したいモデルファイル(.safetensors)と同じフォルダに保存してください。
ダウンロードしたら、ターミナルでスクリプトのあるフォルダに cd してから実行してください。
macOS / Linux
# スクリプトをダウンロードしたフォルダに移動
cd ~/Downloads
# SD 1.5 モデルの場合
bash convert-to-onnx.sh your-model.safetensors sd15# SDXL モデルの場合
bash convert-to-onnx.sh novaAnimeXL.safetensors sdxl# 自動判別(ファイル名に xl/sdxl を含むかで判定)
bash convert-to-onnx.sh your-model.safetensorsWindows(Git Bash または WSL)
コマンドは macOS / Linux と同じです。Git Bash または WSL から実行してください。
bash convert-to-onnx.sh your-model.safetensors sd15スクリプトが行う処理
- Python 3.10〜3.12 を自動検出
- 仮想環境を作成(
sd-convert-env) - 必要ライブラリをインストール(optimum, diffusers, transformers, torch 等)
- safetensors → diffusers → ONNX に変換
- 重みを weight-only fp16 に変換 + Cast(fp16→fp32) ノード挿入、単一
.onnxファイルとして保存 sd-ready/にリネームして出力
スクリプトが使えない場合(手動手順)
Step 1:Python 3.12 のインストール
python.org から Python 3.12 をインストールしてください。 Windows の場合は 「Add Python to PATH」にチェックを忘れずに。
Step 2:仮想環境 + ライブラリインストール
Windows(コマンドプロンプト)
python -m venv sd-convert-env
sd-convert-env\Scripts\activate
pip install "optimum[onnxruntime]" diffusers transformers torch --extra-index-url https://download.pytorch.org/whl/cpumacOS / Linux
python3.12 -m venv sd-convert-env
source sd-convert-env/bin/activate
pip install "optimum[onnxruntime]" diffusers transformers torch --extra-index-url https://download.pytorch.org/whl/cpuStep 3:変換コマンド
SD 1.5
python3 -c "
from diffusers import StableDiffusionPipeline; import torch
pipe = StableDiffusionPipeline.from_single_file('your-model.safetensors', torch_dtype=torch.float16)
pipe.save_pretrained('./model-diffusers')
"
optimum-cli export onnx --model ./model-diffusers --task stable-diffusion ./model-onnxSDXL
python3 -c "
from diffusers import StableDiffusionXLPipeline; import torch
pipe = StableDiffusionXLPipeline.from_single_file('your-sdxl-model.safetensors', torch_dtype=torch.float16)
pipe.save_pretrained('./model-diffusers')
"
optimum-cli export onnx --model ./model-diffusers --task stable-diffusion-xl ./model-onnxWindows の場合は python3 を python に読み替えてください。
Step 4:外部データ統合 + fp16 変換
model-onnx/ 内に .onnx_data ファイルがある場合(SDXL で多い)、以下で統合と fp16 変換を行います。
pip install onnx
python3 -c "
import onnx, os, numpy as np
for sub in ['unet', 'text_encoder_2']:
path = f'model-onnx/{sub}/model.onnx'
data = path + '_data'
if not os.path.exists(data): continue
print(f'Merging {sub}...')
m = onnx.load(path, load_external_data=True)
# fp16 conversion for large models
for init in m.graph.initializer:
if init.data_type == 1: # FLOAT
arr = np.frombuffer(init.raw_data, dtype=np.float32).astype(np.float16)
init.raw_data = arr.tobytes()
init.data_type = 10 # FLOAT16
onnx.save_model(m, f'model-onnx/{sub}/model_fp16.onnx', save_as_external_data=False)
print(f' {sub} done')
print('All done!')
"Step 5:リネーム
SD 1.5(macOS / Linux)
mkdir -p sd-ready
cp model-onnx/text_encoder/model.onnx sd-ready/text_encoder.onnx
cp model-onnx/unet/model.onnx sd-ready/unet.onnx
cp model-onnx/vae_decoder/model.onnx sd-ready/vae_decoder.onnx
cp model-onnx/tokenizer/vocab.json sd-ready/vocab.json
cp model-onnx/tokenizer/merges.txt sd-ready/merges.txtSDXL(macOS / Linux)
mkdir -p sd-ready
cp model-onnx/text_encoder/model.onnx sd-ready/text_encoder.onnx
cp model-onnx/text_encoder_2/model_fp16.onnx sd-ready/text_encoder_2.onnx
cp model-onnx/unet/model_fp16.onnx sd-ready/unet.onnx
cp model-onnx/vae_decoder/model.onnx sd-ready/vae_decoder.onnx
cp model-onnx/tokenizer/vocab.json sd-ready/vocab.json
cp model-onnx/tokenizer/merges.txt sd-ready/merges.txtWindows の場合は cp → copy、mkdir -p → mkdir、/ → \ に読み替えてください。
sd.keydrop.net にアップロード
- sd.keydrop.net を開く
sd-ready/フォルダ内のすべてのファイルを生成タブのドロップエリアにドラッグ&ドロップ- 世代を選択(SD 1.5 系なら SD1.5、SDXL 系なら SDXL)
- 「モデルを読み込む」をクリック
- 読み込みが完了したらプロンプトを入力して生成
| パラメータ | SD 1.5 推奨値 | SDXL 推奨値 |
|---|---|---|
| 幅 × 高さ | 512 × 512 | 1024 × 1024 |
| Steps | 20〜30 | 20〜30 |
| CFG Scale | 7〜10 | 7 |
| VRAM 目安 | 6GB 以上 | 8GB 以上 |
トラブルシューティング
RuntimeError: Error(s) in loading state_dict
原因:モデルの形式がコマンドと合っていない(SD 1.5 のコマンドで SDXL を変換しようとしている等)。
対処:モデルの種類を CivitAI のページで確認し、正しい世代(sd15 / sdxl)を指定してください。
torch.cuda.OutOfMemoryError / メモリ不足
対処:他のアプリを閉じてメモリを解放してください。SDXL の変換には RAM 16GB 以上を推奨します。
ModuleNotFoundError: No module named 'xxx'
対処:仮想環境が有効か確認し、ライブラリのインストールコマンドを再実行してください。
FileNotFoundError: 'your-model.safetensors'
対処:ファイルパスが正しいか確認してください。スクリプト使用時はフルパスを指定するのが確実です。
protobuf serialize error / Message serialization exceeded maximum protobuf size
原因:ONNX ファイルが 2GB の protobuf 上限を超えている(SDXL の UNet 等)。
対処:fp16 変換が必要です。スクリプトを使えば自動で処理されます。手動の場合は Step 4 の fp16 変換を実行してください。
NormalizedConfig.__init__() got multiple values for argument
原因:Python 3.13 以上を使っている。 対処:Python 3.12 で仮想環境を作り直してください。
Validation ... max diff = ... / the model was saved nonetheless
これはエラーではありません。変換は成功しています。
fp16 の丸め誤差が許容値を超えたという警告ですが、the model was saved nonetheless と表示されていればファイルは正常に出力されています。
LoRA マージ済みモデルの変換
sd.keydrop.net の LoRA マージツールで出力した *-merged.safetensors も、同じスクリプトで変換できます。
bash scripts/convert-to-onnx.sh ~/Downloads/v1-5-pruned-emaonly-merged.safetensors sd15設定
「設定」タブから以下を変更できます:
推論エンジン
現在対応しているエンジンは ONNX Runtime Web のみです。 Transformers.js / Ratchet はスタブとして存在しますが、SD パイプライン非対応のため選択できません。
言語
日本語(既定)/ 英語を切り替えられます。ブラウザの navigator.language から自動判定しますが、手動で変更した場合は localStorage に保存されます。
テーマ
ライトモード / ダークモードを切り替えます。OS のカラースキーム設定にも追従します。
利用統計(GA4)
「基本計測」(デフォルト ON)と「詳細計測」(デフォルト OFF、オプトイン)の 2 段階。
- 基本計測: 生成ボタン押下数、画像 DL 数(匿名カウンターのみ)
- 詳細計測: エラーログ、プロンプト本文、モデル名(明示的にオンにしない限り送信されない)
ブラウザの Do Not Track 設定は自動的に尊重されます。
生成履歴
生成した画像は IndexedDB に自動保存されます(画像 Blob + 全パラメータ)。 設定タブの「History management」カードで直近 30 件をサムネイル付きで確認できます。
「Clear all history」ボタンで一括削除できます(確認ダイアログ付き)。 履歴はブラウザ内のみに保存され、外部には送信されません。
ストレージ管理
設定タブの「Storage management」カードで、OPFS に保存されたモデルファイルの管理ができます:
- OPFS 使用量とクォータの表示
- キャッシュ済みファイル一覧(名前 / サイズ / 日時)
- ファイルごとの個別削除
トラブルシューティング
Missing required ONNX components
原因: ファイル名に text_encoder / unet / vae が含まれていない、またはファイルが足りない。
対処: ファイル名を確認し、必要なら手動リネーム。エラーメッセージには各ファイルの分類結果が診断情報として含まれます。
WebAssembly.Module doesn't parse
原因: ORT の WASM ファイルが正しく配信されていない。
対処: 開発サーバの場合、vite-plugin-static-copy が設定されているか確認。本番の場合、/ort-wasm/ パスが有効か確認。
GPU VRAM が不足しています
対処:
- 画像サイズを小さくする(512×512 → 384×384)
- 他のタブやアプリを閉じて VRAM を解放
- fp16 量子化されたモデルを使う(SD-Turbo は既に fp16)
画質が悪い / ノイズだらけ
原因:
- SD 1.5 系は Steps 20〜50 が必要(SD-Turbo は 1〜4 で OK)
- 画像サイズが学習解像度と合っていない(SD 1.5 は 512、SDXL は 1024)
- CFG Scale が不適切(SD 1.5 では 7〜10 が一般的、SD-Turbo は 0)
OPFS に保存したのに消えた
ブラウザの「閲覧データの削除」設定や、シークレットウィンドウの利用が原因です。通常ウィンドウを使い、設定を確認してください。
LoRA マージで unmatched modules が多い
LoRA のキー命名規則とベースモデルのテンソル名が一致していない可能性があります。 現状のマッピングは Kohya 形式(SD 1.5 系)を前提としています。SDXL 向け LoRA や独自命名の LoRA は未対応のことがあります。
プライバシー
送信されないもの
- アップロードされたモデルファイル / LoRA ファイル本体
- 生成された画像
- 生成履歴
送信される可能性があるもの(GA4)
- 基本計測(デフォルト ON): 生成ボタン押下数 / 画像 DL 数(匿名メタ付き)
- 詳細計測(オプトイン、デフォルト OFF): エラーログ / プロンプト / モデル名
設定画面からいつでも無効化可能。Do Not Track も尊重。VITE_GA_MEASUREMENT_ID 未設定のビルドでは計測機能は完全無効です。
Tips
Seed を固定して微調整
同じ Seed で Steps や CFG Scale だけを変えると、構図を保ったまま品質を調整できます。
LoRA の weight を段階的に変える
weight=0.3 → 0.5 → 1.0 と段階的にマージして効果を確認すると、過剰適用を防げます。
OPFS キャッシュの活用
モデルロードは初回だけ時間がかかりますが、OPFS に保存されれば 2 回目以降は数秒で復元できます。「📦 Load from OPFS cache」を活用しましょう。
複数モデルの切替
別のモデルを試すには、ページをリロードしてから新しいファイルをドロップしてください。現状、複数モデルの同時保持には対応していません。
PNG メタデータの活用
生成画像の PNG ファイルには生成条件が自動記録されています。「この画像、どんな設定で作ったっけ?」と思ったら、AUTOMATIC1111 の PNG Info やフリーツールで確認できます。